Most Recent
Most Popular
Highest Rated
Reset



















Lessons
view all ⭢




lesson
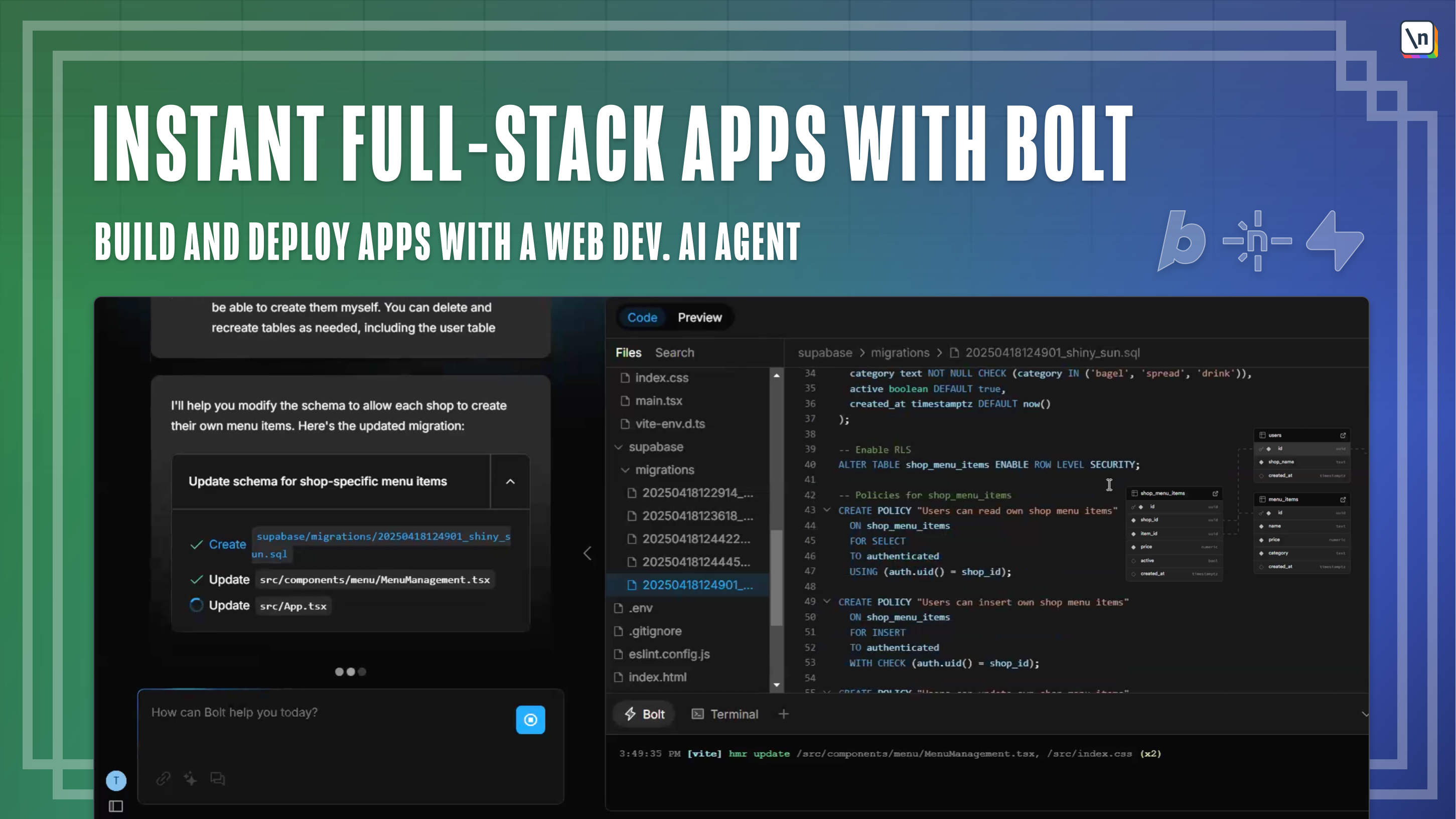
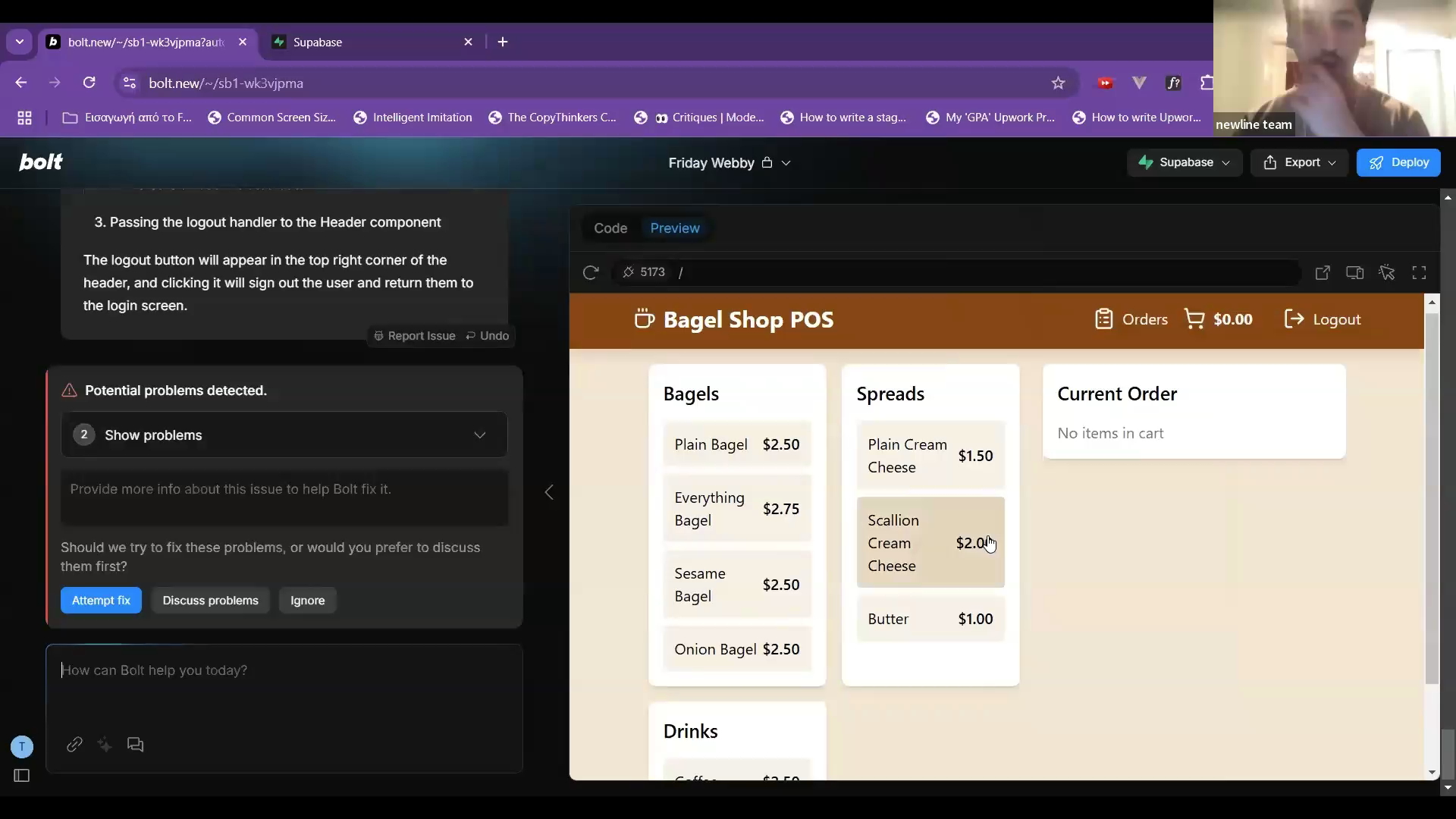
How To Debug Your App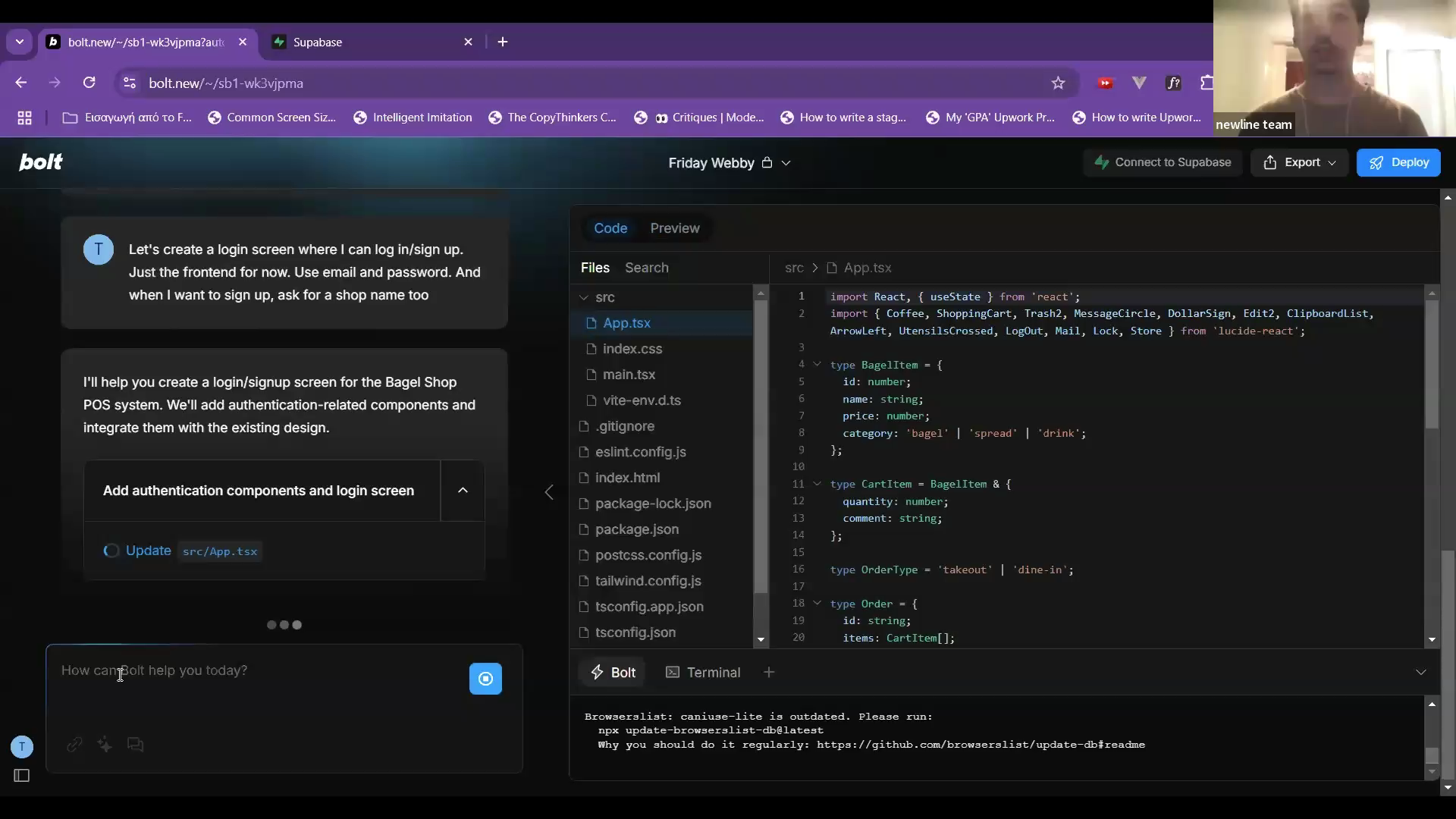
lesson
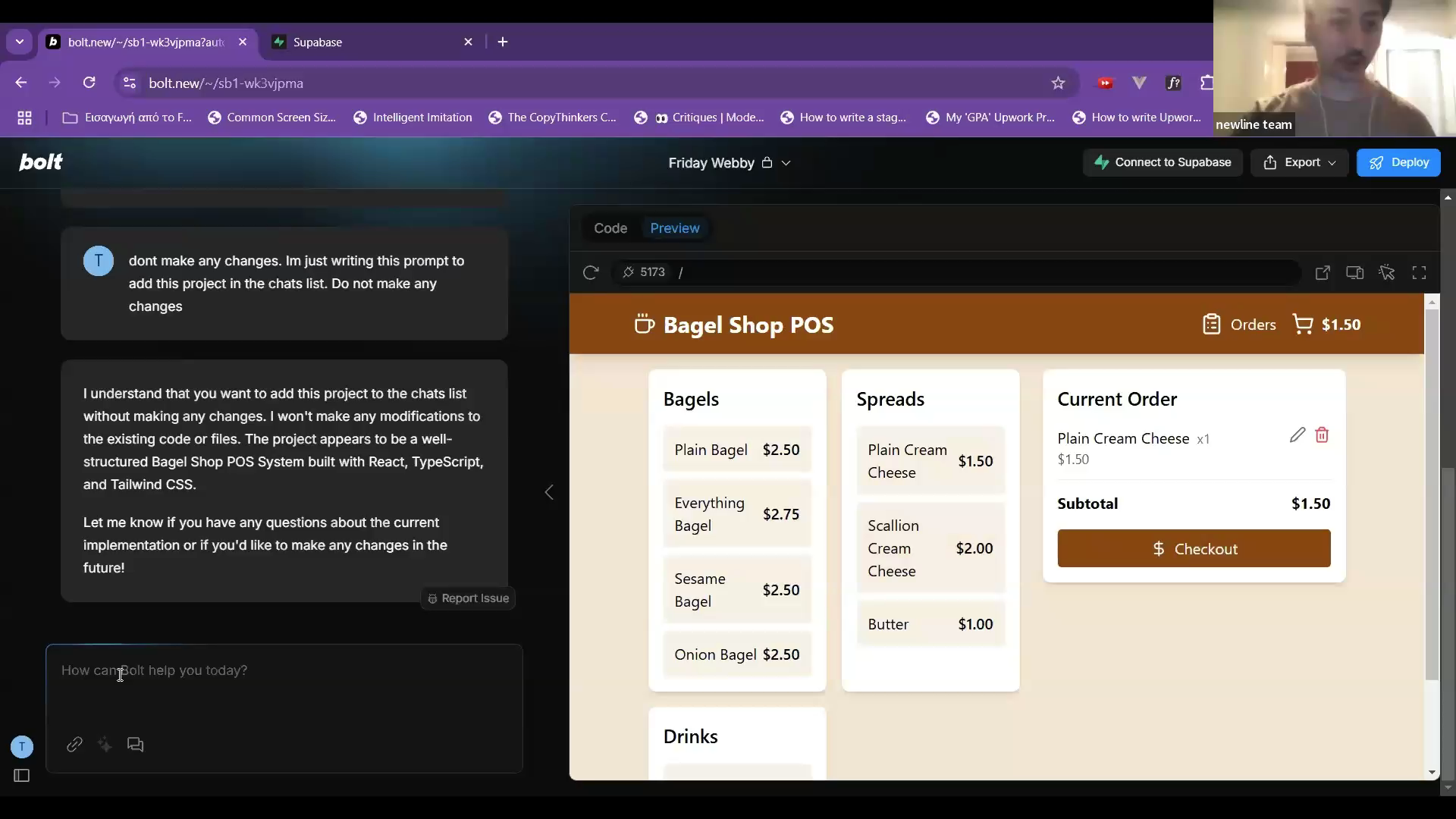
Adding Authentication

lesson
Supabase > Firebase
lesson
What Is Supabase?
Articles
view all ⭢uncertainty_aware_ai_models
two_level_uncertainty
safe_ai_ranking_models
two_level_uncertainty_framework
ai_ranking_framework
ai_ranking_model_safety
non_stationarity_in_ai
strategy_level_regime_trust
positional_safety_ai
ai_model_risk_management
prompt_engineering_methods
llm_fine_tuning_strategies
advanced_rag_frameworks
enterprise_ai_solutions
claude_mythos_release_date
anthropic_ai_model
ai_model_benchmarks
claude_mythos
ai_inference_techniques
ai_cybersecurity_applications
ai_system_risks
multi_agent_systems
ai_agent_cooperation
ai_cooperation_strategies
non_cooperative_ai_agents
autonomous_ai_behavior
types_of_ai_agents
ai_hosting_savings
ai_cost_optimization
ai_hosting_costs
ai_inference_costs
ai_model_hosting
ai_deployment_costs
ai_storage_fees
ai_operational_expenses
llm_hosting_expenses
model_training_costs
rag_frameworks
data_privacy_in_ai
hybrid_training_methods
synthetic_data_for_llm_training
ai_model_optimization
fine_tuning_llms_techniques
llm_products
prompt_engineering_techniques
ai_agent_interaction
ai_memory_systems
rag
memory_driven_ai
contextual_ai_agents
ai_agent_memory
types_of_ai_agents
building_ai_applications
prompt_engineering_techniques
ai_agent_efficiency
ai_inferences
fine_tuning_llms
prompt_engineering_techniques
n8n_framework
llm_text_pattern_detection
text_anomaly_detection
ai_applications
ai_efficiency
rag
unexpected_text_patterns
ai_error_detection
prompt_engineering_techniques
llms_for_error_detection
math_proof_counterexamples
large_language_models
building_ai_applications
ai_in_mathematical_research
google_colab_ai_prototyping
ai_workflow_tools
llm_fine_tuning_techniques
ai_model_deployment
cloud_free_ai_development
prompt_engineering
rag_frameworks
feature_testing_automation
codex_ai_development
codex_testing_efficiency
parallel_testing_ai
automate_qa_testing
codex_subagents_benefits
ai_testing_workflows
codex_subagents
ai_breach_prevention
sandboxed_ai_agents
ai_agent_protection
nemoclaw_installation
nemoclaw
ai_security
openclaw_vulnerabilities
secure_ai_deployment
knowledge_graph
ai_applications
fine_tuning_llms
prompt_engineering_techniques
steereval
ai_output_precision
llm_controllability
rag
ai_inferences
ai_coding_platforms